-
회사에서 쿠버네티스를 도입하며 지금까지 미뤄두었던 쿠버네티스에 대한 학습이 필요했기 때문에 이번 기회에 쿠버네티스를 사용하는데 필요한 기본적인 개념들에 대해 공부했습니다.
이번 글은 공부한 내용을 정리하는 글이며 목차는 아래와 같습니다.
7. 그 외 기능 (Label, ConfigMap, Secret)
이번 글에서는 Controller 까지 알아보고 다음 글에서 나머지 내용에 대해 알아보도록 하겠습니다.
쿠버네티스를 공부하기 위해 들었던 강의는 유튜브에서 무료로 제공해주신 따배쿠 강의입니다. 개인적으로 무료이면서도 이정도로 개념을 잡기 좋은 강의가 있나 싶습니다.
https://www.youtube.com/watch?v=6n5obRKsCRQ&list=PLApuRlvrZKohaBHvXAOhUD-RxD0uQ3z0c
처음 공부하시는 분들이라면 한번 쭉 들어보시는걸 추천하면서 실습 환경 구성 방법부터 진행하도록 하겠습니다.
1. 실습 환경 구성 방법
- 실습은 가상머신 3개를 이용해서 진행했습니다.
- 1개는 master node, 2개는 worker node로 사용했습니다.
- 각 node 들은 kubernetes의 최소 권장사양인 2CPU, 2GM RAM으로 설정했습니다.
- 제가 사용한 노트북은 macOS m1 칩이었기 때문에 UTM을 이용해 가상머신을 생성하였고 Ubuntu 22.04 버전을 이용했습니다.
[ UTM을 통한 가상머신 설치 ]
MAC M1 Chip PC에서 UTM 가상머신 사용하기 및 Ubuntu 20.04 설치
[ kubernetes 설치 환경 구성 및 필요 패키지 설치 ]
기본적으로 모든 node에 도커를 설치해야 합니다.
Install Docker Engine on Ubuntu
다음으로 kubernetes 공식문서를 따라 설치를 진행해주는데 중간에 swap 메모리를 해제하고 방화벽을 해제하는 절차가 필요합니다.
- 실습 환경이었기 때문에 방화벽은 해제하고 진행했습니다. 운영환경이라면 필요한 방화벽만 오픈하면 될것 같습니다.
- swap 메모리 해제에 관한 글입니다.
쿠버네티스 환경 설정
쿠버네티스 환경 설정
velog.io
sudo apt-get update sudo apt-get install -y apt-transport-https ca-certificates curl sudo curl -fsSLo /etc/apt/keyrings/kubernetes-archive-keyring.gpg <https://packages.cloud.google.com/apt/doc/apt-key.gpg> echo "deb [signed-by=/etc/apt/keyrings/kubernetes-archive-keyring.gpg] <https://apt.kubernetes.io/> kubernetes-xenial main" | sudo tee /etc/apt/sources.list.d/kubernetes.list -- swap 메모리 해제 sudo swapoff -a && sudo sed -i '/swap/s/^/#/' /etc/fstab -- 방화벽 해제 sudo ufw disable sudo ufw status sudo apt-get update sudo apt-get install -y kubelet kubeadm kubectl sudo apt-mark hold kubelet kubeadm kubectlInstalling kubeadm
This page shows how to install the kubeadm toolbox. For information on how to create a cluster with kubeadm once you have performed this installation process, see the Creating a cluster with kubeadm page. Before you begin A compatible Linux host. The Kuber
kubernetes.io
컨테이너 런타임 설치
- 파드가 노드에서 실행될 수 있도록 클러스터의 각 노드에 컨테이너 런타임을 설치해야 합니다.
- 도커 엔진을 사용할 것이기 때문에 cri-docker를 각 노드에 설치해주어야 합니다.
- 컨테이너 런타임에 대한 자세한 설명은 아래 공식문서를 보면 참고하면 좋을것 같습니다.
wget <https://github.com/Mirantis/cri-dockerd/releases/download/v0.3.1/cri-dockerd-0.3.1.arm64.tgz> tar -xf cri-dockerd-0.3.1.arm64.tgz sudo mv cri-dockerd/cri-dockerd /usr/local/bin/ wget <https://raw.githubusercontent.com/Mirantis/cri-dockerd/master/packaging/systemd/cri-docker.service> wget <https://raw.githubusercontent.com/Mirantis/cri-dockerd/master/packaging/systemd/cri-docker.socket> sudo mv cri-docker.socket cri-docker.service /etc/systemd/system/ sudo sed -i -e 's,/usr/bin/cri-dockerd,/usr/local/bin/cri-dockerd,' /etc/systemd/system/cri-docker.service sudo systemctl daemon-reload sudo systemctl enable cri-docker.service sudo systemctl enable --now cri-docker.socket systemctl status cri-docker.socket아래 블로그를 참고하여 cri-docker를 설치했습니다.
https://computingforgeeks.com/install-mirantis-cri-dockerd-as-docker-engine-shim-for-kubernetes/
[ kubeadmin cluster 구성 → master node 에서만 실행합니다 ]
- kubeadm init ~~
- kubeadmin 을 통해 master 노드에 api, controller, scheduler, coreDNS, etcd 등을 설치할 수 있습니다.
- 참고로 컨테이너 런타임으로 cri-docker를 사용하기 때문에 추가 옵션을 넣어줍니다.
sudo kubeadm init --cri-socket "unix:///var/run/cri-dockerd.sock"- 위 명령어를 작성하면 필요한 pod 들을 설치하며 마지막에 아래와 같은 내용이 나옵니다.
- root 계정이 아니라면 설명에 따라 3개의 명령어를 실행시켜주면 됩니다.
- 추가로 kubeadm join ~~ 부분은 따로 복사해두고 나중에 worker node에서 실행시켜 cluster 구성을 진행합니다.
Your Kubernetes control-plane has initialized successfully! To start using your cluster, you need to run the following as a regular user: mkdir -p $HOME/.kube sudo cp -i /etc/kubernetes/admin.conf $HOME/.kube/config sudo chown $(id -u):$(id -g) $HOME/.kube/config You should now deploy a Pod network to the cluster. Run "kubectl apply -f [podnetwork].yaml" with one of the options listed at: /docs/concepts/cluster-administration/addons/ You can now join any number of machines by running the following on each node as root: kubeadm join <control-plane-host>:<control-plane-port> --token <token> --discovery-token-ca-cert-hash sha256:<hash>
Creating a cluster with kubeadm
CNI(Container Network Interface)
- Container 간 통신을 지원하며, Pod Network 라고도 불립니다.
- 다양한 종류의 플러그인이 존재합니다. ex) flannel, calico, weavenet …
- 아래 글은 CNI에 관해 자세히 설명한 글입니다.
Creating a cluster with kubeadm
- calico CNI 설치
- 여러 CNI 기술 중 calico를 사용했습니다.
curl <https://raw.githubusercontent.com/projectcalico/calico/v3.25.0/manifests/calico.yaml> -O kubectl apply -f calico.yaml[ worker node 구성 → root 권한으로 진행해야 합니다 ]
- worker node 에서 위에서 복사한 kubedadm join ~~ 부분을 실행해 줍니다.
- 이때 마찬가지로 컨테이너 런타임으로 cri-docker를 사용하기 때문에 --cri-socket 이라는 추가옵션을 줍니다.
- 예시 문은 아래와 같습니다. 참고해서 각자 환경에 맞게 작성해주면 됩니다.
kubeadm join 192.168.64.7:6443 --token l4qxru.lpq1sf05gx33g0ub \\ --discovery-token-ca-cert-hash sha256:30870ae699ee31ae17409f25c8de8a8177ff55d0a08d448a89eb0b01102b0290 --cri-socket "unix:///var/run/cri-dockerd.sock"[ 명렁어 자동완성 ]
- 추가로 kubectl 명령어는 기본적으로 shell 에서 자동완성을 지원하지 않습니다.
- 아래 설정을 통해 tab으로 자동완성 기능을 사용할 수 있습니다.
source <(kubectl completion bash) echo 'source <(kubectl completion bash)' >>~/.bashrc위 과정을 통해 실습 환경을 구성할 수 있었습니다. 이후에는 본격적으로 쿠버네티스가 어떻게 구성되어 있고 각각의 역할에 대해 알아보도록 하겠습니다.
2. 쿠버네티스 기본
쿠버네티스 구성 요소
- 쿠버네티스를 배포하면 클러스터를 얻을 수 있는데 클러스터의 구성 요소는 아래 사진과 같습니다.
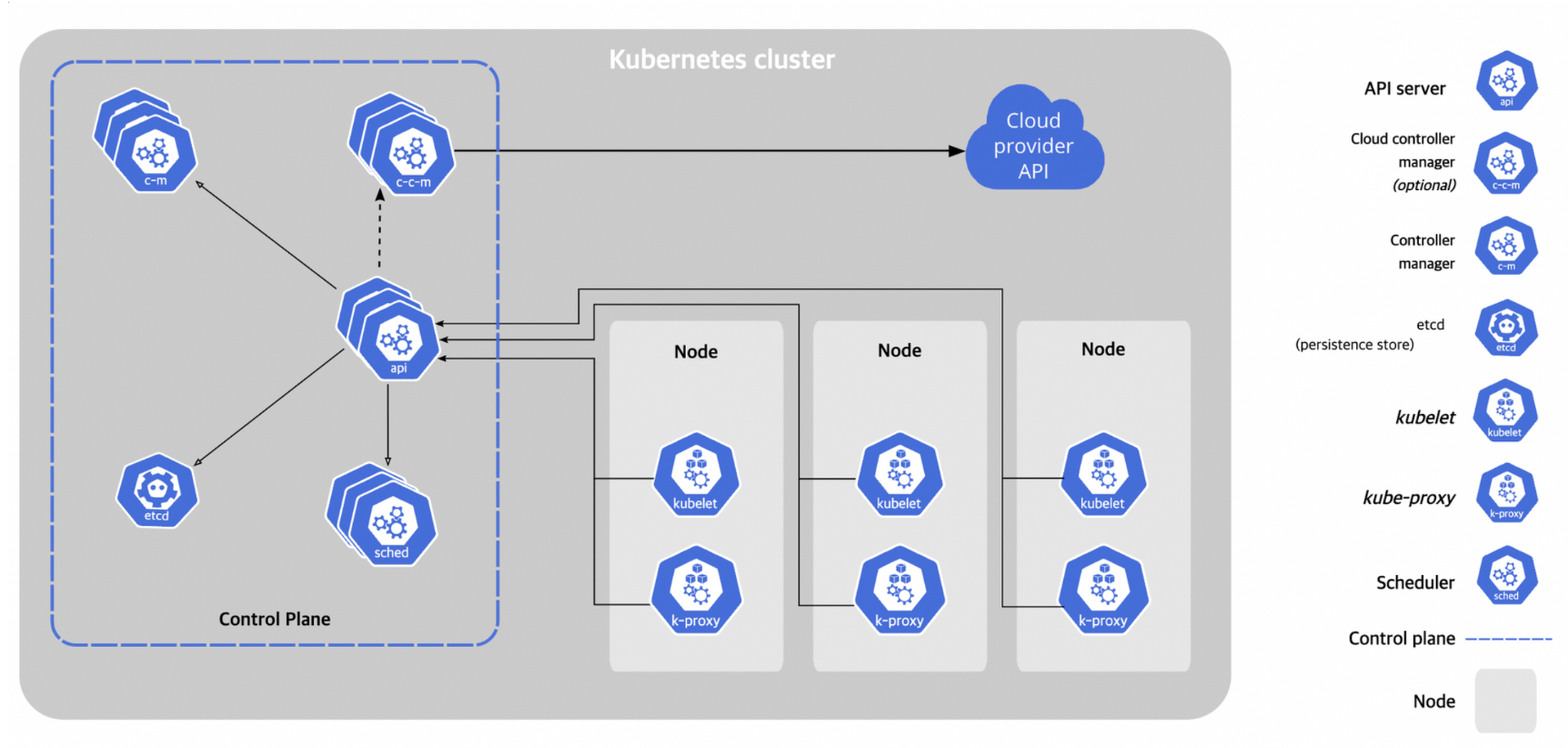
- kube-apiserver
- worker node의 kubelet 사이를 통신해주는 역할을 합니다.
- 사용자가 kubectl을 사용할 때 요청을 받아서 처리하는 역할을 합니다.
- etcd
- 모든 클러스터 데이터를 담는 쿠버네티스 뒷단의 저장소입니다.
- Key - Value 형태의 저장소입니다.
- kube-scheduler
- 노드가 배정되지 않은 새로 생성된 파드를 감지하고, 실행할 노드를 선택하는 역할을 합니다.
- kube-controller-manager
- kubernetes의 resource(node, replicaset, pod, service …)를 모니터링하며 관리합니다.
kubectl 기본 명령어
kubectl 명령어 기본 구조
- kubctl [ command ] [ TYPE ] [ NAME ] [ flags ]
- command : 자원에 실행할 명령 (create, get, delete, edit … )
- TYPE : 자원의 타입 (node, pod, service …)
- NAME : 자원의 이름
- flags : 부가적으로 설정할 옵션
컨테이너 파드를 만드는 명령어
- kubectl run webserver --image=nginx:1.14 --port 80 → webserver 이름의 pod 생성
- kubectl create -f webserver-pod.yaml (yaml 파일로 만들기)
deployment를 이용해 파드를 만드는 명령어 replicas를 설정할 수 있다.
- kubectl create deployment mainui --image=httpd --replicas=3
webserver 라는 파드의 컨테이너로 들어가서 명령어 실행하는 방법
- kubectl exec webserver -it -- /bin/bash
네임스페이스 사용하기
- 네임스페이스란 동일한 쿠버네티스 물리 클러스터를 기반으로 하는 여러 가상 클러스터를 의미합니다.
- 쿠버네티스 클러스터내에서 논리적인 분리 단위이며 쿠버네티스의 네임스페이스 별로 리소스가 구분되어 있습니다.
- 기본 네임스페이스는 default 입니다.
네임스페이스 목록 확인
- kubectl get namespaces
kubectl get pod -n default → default 네임스페이스의 pod를 가져온다.
- 기본이 default임
3. Pod
컨테이너를 표현하는 kubernetes API의 최소 단위
Pod에는 하나 또는 여러 개의 컨테이너가 포함될 수 있습니다.
kubectl run ~ 또는 kubectl create -f ~.yml 명령어를 통해 pod를 실행할 수 있습니다.
Pod의 여러 설정들
- multi - pod
- liveness Probe
- init container
- infra container
- static pod
- 리소스 할당 및 환경변수 설정
- Pod 구성 패턴의 종류
지금부터 각각의 설정들에 대해 알아보겠습니다.
[ multi -pod ]

- 위 사진에서 multipod의 경우 nginx, centos 컨테이너 2개가 작동중인 pod 입니다.
- 여기서 확인할 부분은 multipod에 있는 IP는 1개라는 것입니다. 즉, nginx와 centos는 같은 IP를 사용하고 있습니다.
- 아래는 multipod를 생성하기 위한 pod-multi.yaml 파일의 모습이며 kubectl create -f pod-multi.yaml 명령어를 통해 pod를 생성할 수 있습니다.
apiVersion: v1 kind: Pod metadata: name: multipod spec: containers: - name: nginx-container image: nginx:1.14 ports: - containerPort: 80 - name: centos-container image: centos:7 command: - sleep - "10000"[ liveness Probe -> self healing pod ]
- pod가 계속 실행할 수 있음을 보장합니다.
- yaml 파일에서 spec 부분에 정의하며, 서비스마다 self-healing 방법이 다릅니다.
- 웹서버라면 http 요청, db라면 데이터 존재 확인 등 서로 체크하는 방법이 다릅니다.
- httpGet, tcpSocket, exec 매커니즘으로 표현할 수 있습니다.
- 해당 요청에 문제가 생긴다면 컨테이너를 리스타트 합니다.
- 추가로 initialDelaySeconds, periodSeconds, timeoutSeconds, successThreshold, FailureThreshold 등의 속성도 추가할 수 있습니다.
문제가 있을 때 pod를 재실행하는 것이 아니라 컨테이너를 재실행 합니다. 즉, pod의 ip가 변경되는 것이 아니라 내부 컨테이너만 다시 pull 해서 실행시킵니다.
apiVersion: v1 kind: Pod metadata: name: liveness-pod spec: containers: - image: smlinux/unhealthy name: unhealthy-container ports: - containerPort: 8080 protocol: TCP livenessProbe: httpGet: path: / port: 8080 initialDelaySeconds: 15 periodSeconds: 20[ init container를 적용한 pod ]
- init container를 적용하면 해당 initContainers 부분의 컨테이너가 차례대로 전부 실행이 되어야 최종 pod가 실행됩니다.
apiVersion: v1 kind: Pod metadata: name: myapp-pod labels: app.kubernetes.io/name: MyApp spec: containers: - name: myapp-container image: busybox:1.28 command: ['sh', '-c', 'echo The app is running! && sleep 3600'] initContainers: - name: init-myservice image: busybox:1.28 command: ['sh', '-c', "until nslookup myservice.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for myservice; sleep 2; done"] - name: init-mydb image: busybox:1.28 command: ['sh', '-c', "until nslookup mydb.$(cat /var/run/secrets/kubernetes.io/serviceaccount/namespace).svc.cluster.local; do echo waiting for mydb; sleep 2; done"]- 각 initContainers가 성공해야 myapp-container가 실행됩니다.
- 아래 사진은 init-myservice는 성공했지만 init-mydb는 성공하지 않은 상태입니다.

- 만약 모든 initContainers가 성공하면 아래 사진처럼 실행되게 됩니다.

[ infra container (pause) ]
- 만약 pod에 nginx 컨테이너가 있다면, 사실은 내부에 pause 컨테이너가 하나 더 있습니다.
- 즉, pause 컨테이너는 pod가 생성될 때 pod당 1개씩 생성됩니다.
- pause 컨테이너는 pod에 대한 인프라, ip 등을 관리 및 생성해주는 컨테이너입니다.
- 아래 사진은 nginx 컨테이너를 실행시키는 pod를 생성한 직후의 node1의 모습입니다. 사진을 보면 /pause가 nginx 실행과 같은 시간에 생성된 것을 확인할 수 있습니다.

[ static pod ]
- static pod는 control-plane의 api에 요청을 하는 형태로 생성하는 것이 아닙니다.
- 바로 각 node에는 kubelet이라는 데몬이 동작하는데 이때 kubelet이 관리하는 static pod관련 디렉터리에 yaml 파일을 넣어두면 kubelet 데몬이 알아서 pod를 만들어 줍니다.
- yaml 파일을 삭제하면 pod도 삭제해줍니다.
- 즉, kubelet 데몬에서 pod를 생성, 삭제해주는 것입니다.
- 각 노드에서 /var/lib/kubelet/config.yaml 파일에서 staticPodPath 속성을 통해 static pod 관련 디렉터리를 확인할 수 있습니다.
- yaml 파일을 해당 디렉터리에 저장하는 순간 바로 control-plane의 api 도움 없이 바로 pod가 생성됩니다.
- 아래 사진은 master-node의 static pod 관련 디렉터리의 파일 모습입니다.
- control-plane의 구성요소 생성에 관한 yaml 파일들을 확인할 수 있습니다.

참고로 control-plane의 static pod에 nginx.yaml 같은 파일을 생성한다면, 이는 control-plane에서 생성되는 것이 아니라 다른 node에 자동으로 생성됩니다.
[ 리소스 할당 및 환경변수 설정 ]
리소스 할당
- 한 노드에 여러 pod를 리소스 제한 없이 실행하게 된다면 특정 pod에서 노드의 모든 리소스를 사용하여 다른 pod가 제대로 동작하지 못하는 경우가 있을 수 있습니다. 따라서 반드시 pod에 리소스를 제한해야 합니다.
- Resource Request : 파드를 실행하기 위한 최소 리소스 양을 요청합니다.
- Resource Limits : 파드가 사용할 수 있는 최대 리소스 양을 제한합니다. memory limit 을 초과해서 사용되는 파드는 종료되며 다시 스케줄링 됩니다, 따라서 너무 타이트하게 limits을 설정하면 안됩니다.
- 만약 requests만 설정하면 limits는 따로 설정되지 않지만, limits만 설정하면 동일한 리소스로 requests가 설정됩니다.
apiVersion: v1 kind: Pod metadata: name: nginx-pod-resource spec: containers: - name: nginx-container image: nginx:1.14 ports: - containerPort: 80 protocol: TCP resources: requests: cpu: 200m memory: 500Mi limits: cpu: 1 memory: 1Gi1MB = 1024KB ??? → 사실 1MB = 1000KB 이다. 1MiB = 1024KiB 이다. 이때 쿠버네티스에서는 B를 뺀 1Mi라고 작성한다.(Mi, Gi …)
1 core = 1000mc 쿠버네티스에서는 c를 뺀 200m 으로 작성한다. core의 경우 생략한다.환경변수 설정
- 환경변수란
- pod 내의 컨테이너가 실행될 때 필요로 하는 변수를 의미합니다.
- 컨테이너 제작 시 미리 정의하며
- pod 실행 시 미리 정의된 컨테이너 환경변수를 변경할 수 있습니다.
apiVersion: v1 kind: Pod metadata: name: nginx-pod-env spec: containers: - name: nginx-container image: nginx:1.14 ports: - containerPort: 80 protocol: TCP env: - name: MYVAR value: "testvalue" resources: requests: cpu: 200m memory: 500Mi[ multi - Pod 구성 패턴의 종류 ]
multi - pod 의 패턴에는 아래와 같은 패턴들이 존재합니다.
- Sidecar
- 원래 사용하려던 기본 컨테이너 기능 확장 또는 강화하는 용도의 컨테이너 추가
- 웹 서버 컨테이너 : 로그를 파일로 남김
- 로그 수집 컨테이너 : 파일시스템에 샇이는 로그를 수집하여 외부 로그 수집기로 이전송
- Ambassador
- pod 안에서 프록시 역할을 하는 컨테이너를 추가하는 패턴
- 앱 컨테이너 : 외부에서 접근하는 경우 ambassador 컨테이너를 통해서 연결되도록 설정
- ambassador 컨테이너 : 프록시 또는 로드밸런서 역할 수행
- Adapter
- 메인 컨테이너의 출력을 표준화시킵니다.
- 앱 컨테이너 : cpu, ram 사용량 등의 정보 존재
- adapter 컨테이너 : 해당 정보중 monitoring 시스템에 보여주고 싶은 정보들만 가공해서 보여줄 수 있습니다. 즉, 앱 컨테이너의 출력은 변환하지 않고 adapter 컨테이너의 출력을 수정해서 보여줄 수 있습니다.

4. Controller
pod에서 liveness Probe를 통해 컨테이너의 지속성을 보장한 것을 확인했습니다.
근데 만약 노드 자체에 문제가 발생하는 경우 kubelet이 노드 자체에서 실행되기 때문에 노드가 실패하면 컨테이너를 다시 실행할 수 없습니다.
이러한 경우 쿠버네티스는 pod를 항상 실행되도록 유지하기 위해 Controller를 사용합니다.
즉, 컨트롤러는 각각의 pod를 관리하는 역할을 합니다.
쿠버네티스에서 아래 항목들에 관한 컨트롤러를 제공합니다.
- Replication Controller
- ReplicaSet
- Deployment
- Daemonset
- StatefulSet
- Job Controller
- CronJob Controller

지금부터 쿠버네티스에서 제공하는 컨트롤러에 대해 알아보겠습니다.
[ ReplicationController ]
- Pod의 개수를 보장
- 요구하는 pod의 개수를 보장하며 pod 집합의 실행을 항상 안정적으로 유지하는 것을 목표로 합니다.
- 요구하는 pod의 개수가 부족하면 pod를 추가하며, 반대로 요구하는 pod의 개수보다 많다면 최근에 생성한 pod를 삭제합니다.
apiVersion: v1 kind: ReplicationController metadata: name: rc-nginx spec: replicas: 3 selector: app: webui template: metadata: name: nginx-pod labels: app: webui spec: containers: - name: nginx-container image: nginx:1.14- 위 yaml 파일을 만들어서 실행해준다면 3개의 rc-nginx-… 이름의 pod가 생성될 것이고 각각 webui라는 label을 갖게 됩니다.
- 이때 생성된 pod를 지워도 ReplicationController가 자동으로 파악해서 다시 만들어줍니다. 또한 edit 모드를 통해 replicas를 바꾸게 되면 자동으로 개수를 맞춰줍니다.
추가로 만약 edit 모드에서 nginx:1.15 버전으로 변경한다고 하더라도 기존에 떠있던 pod가 바뀌지는 않습니다. 대신 pod가 삭제되어서 다시 pod가 생성된다면 이때 1.15 버전으로 업그레이드 되어서 생성됩니다. 이것이 롤링 업데이트의 원리입니다.
[ ReplicaSet ]
- ReplicationController와 역할은 거의 동일합니다.
- 차이로는 selector에 풍부한 selector 작성을 가능하게 해줍니다.

ReplicationController, ReplicaSet 설정 yaml 파일 비교 
[ Deployment ]
- ReplicaSet을 이용하면 Pod의 숫자가 보장되기 때문에 관리자가 원하는 어플리케이션을 안정적으로 배포할 수 있습니다.
- 하지만, 시간이 흐르게 되면 해당 어플리케이션을 업그레이드하여 배포해야 하는데 ReaplicaSet은 이런 업데이트 기능은 제공하지 않습니다.
- 이를 해결하기 위해 사용하는 것이 Deployment 입니다.
- 즉, Deployment는 ReplicaSet을 제어해주는 부모 역할을 하며 update를 위해 만들어졌습니다.
- Deployment가 ReplicaSet을 컨트롤하고 ReplicaSet이 pod를 컨트롤합니다.
- 아래 yaml 파일을 보면 ReplicaSet과 Deployment가 거의 차이가 없는 것을 확인할 수 있습니다.

Deployment를 이용한 Rolling update
버전 업이 될 때 새로운 ReplicaSet을 만들고 pod를 1개 추가한 후 기존 pod 1개를 죽입니다
다음으로 또 다른 새로운 버전 pod 1개를 생성하고 기존 pod 1개를 죽입니다.
1개씩 배포할지는 커스텀 가능합니다.
set image 명령어 혹은 yaml 파일 수정을 통해 적용 가능합니다.
- kubectl set image deployment <deploy_name> <container_name>=<new_version_image>
아래 사진은 nginx:1.15 버전을 nginx:1.16 버전으로 업데이트 하는 과정을 나타낸 것입니다.

아래 사진은 추가로 nginx:1.17 버전으로 업데이트 한 후 지금까지의 업데이트 과정을 확인해본 사진입니다.

- yaml 파일을 통한 업데이트 진행
아래 코드 처럼 .spec.strategy 설정을 통해 원하는 업데이트를 진행할 수 있습니다.
현재 1.14 버전이 명시되어 있는데 이후에 1.15로 수정 후 kubectl apply -f ~~.yaml 명령어를 진행하게 되면 자동으로 Rolling update를 진행해줍니다.
apiVersion: apps/v1 kind: Deployment metadata: name: deploy-nginx annotations: kubernetes.io/change-cause: version 1.14 spec: progressDeadlineSeconds: 600 revisionHistoryLimit: 10 strategy: rollingUpdate: maxSurge: 25% maxUnavailable: 25% type: RollingUpdate replicas: 3 selector: matchLabels: app: webui template: metadata: labels: app: webui spec: containers: - name: web image: nginx:1.14 ports: - containerPort: 80- 배포 전략으로 Rolling Update, Recreate, Blue/Green, Canary 배포 등 여러 전략이 있는데 이를 수행할 수 있도록 도와주는 것이 Deployment라고 생각하면 될것 같습니다.
- 아래 블로그에서 배포 전략에 대해 간단하게 설명해주고 있으니 참고해보면 좋겠습니다.
ReplicaSet과 Deployment
Kubernetes의 대표적인 컨트롤러 ReplicaSet과 Deployment에 대해 알아보자
velog.io
[ Daemonset ]
- 전체 노드에서 Pod가 한 개씩 실행되도록 보장해줍니다.
- 로그 수집기, 모니터링 에이전트와 같은 프로그램 실행 시 적용할 수 있습니다.
- 추가로 Rolling Update 기능도 지원해줍니다.
- edit 버전으로 들어가서 이미지 버전을 수정하면 바로 Rolling Update가 됩니다.
- 아래 그림에서 node3가 추가되면 저절로 logagent가 생성되게 해줍니다. 반드시 node 당 1개씩 pod를 보장해줍니다.

apiVersion: apps/v1 kind: DaemonSet metadata: name: daemonset-nginx spec: selector: matchLabels: app: webui template: metadata: name: nginx-pod labels: app: webui spec: containers: - name: nginx-container image: nginx:1.14[ StatefulSet ]
- 이해를 돕기 위해 ReplicaSet과 StatefulSet을 비교해보겠습니다.
- ReplicaSet은 파드가 삭제되면 새로운 이름으로 파드가 생성됩니다.

- 하지만, StatefulSet의 경우 파드이름이 파드이름-0 부터 시작하며 삭제한 파드는 삭제되었던 파드 이름 그대로 다시 생성됩니다.

- 또한 ReplicaSet의 경우 파드수가 증가하면 모든 파드가 동일한 pvc를 바라봅니다.

- 하지만 StatefulSet의 경우 파드가 증가하면, 각 파드는 자기만의 pvc를 갖습니다. 그리고 파드가 다시 실행되어도 한번 연결된 pvc로 게속 연결됩니다.
- 따라서 이런 구조를 이용해 자기만의 스토리지를 필요로 하는 분산 데이터 저장소에 적합합니다.

apiVersion: apps/v1 kind: StatefulSet metadata: name: sf-nginx spec: replicas: 3 serviceName: sf-service # podManagementPolicy: OrderedReady podManagementPolicy: Parallel selector: matchLabels: app: webui template: metadata: name: nginx-pod labels: app: webui spec: containers: - name: nginx-container image: nginx:1.14- 추후에 headless service를 설명할 때 좀 더 자세히 설명하도록 하겠습니다.
- 아래 블로그를 통해 좀더 자세히 StatefulSet에 대해 이해할 수 있습니다.
쿠버네티스 오퍼레이터 스터디 1주차 - statefulset이란
왜 StatefulSet을 사용할까 (feat. deployment와의 차이점)
[ Job Controller ]
- kubernetes는 pod를 running 중인 상태로 유지합니다.
- Batch 처리하는 pod는 작업이 완료되면 종료됩니다.
- Batch 처리에 적합한 컨트롤러로 Pod의 성공적인 완료를 보장해줍니다.
- 비정상 종료 시 다시 실행
- 정상 종료 시 완료

apiVersion: batch/v1 kind: Job metadata: name: centos-job spec: # completions: 5 순차적으로 5번 실행해줌 # parallelism: 2 병렬 방식으로 2개 까지 동시에 실행해줌 #activeDeadlineSeconds: 5 동작하는 작업이 5초 안에 안끝나면 강제로 complete 시킨다. template: spec: containers: - name: centos-container image: centos:7 command: ["bash"] args: - "-c" - "echo 'Hello World'; sleep 50; echo 'Bye'" restartPolicy: Never #restartPolicy: OnFailure # backoffLimit: 3 ---- # restartPolicy에 의해 bashc라는 잘못된 커맨드를 입력했기 때문에 실패를 # 총 3번 하게 되면 그냥 pod를 삭제해 버린다. # OnFailure는 컨테이너를 다시 실행해준다. # Never의 경우는 Pod를 다시 실행해준다. apiVersion: batch/v1 kind: Job metadata: name: centos-job spec: # completions: 5 # parallelism: 2 #activeDeadlineSeconds: 5 template: spec: containers: - name: centos-container image: centos:7 command: ["bashc"] args: - "-c" - "echo 'Hello World'; sleep 50; echo 'Bye'" #restartPolicy: Never restartPolicy: OnFailure backoffLimit: 3[ CronJob Controller ]
- 사용자가 원하는 시간에 JOB 실행을 예약해줍니다.
- job 컨트롤러로 실행할 Application Pod를 주기적으로 반복해서 실행해줍니다.
- Linux의 cronjob의 스케줄링 기능을 Job Controller에 추가한 API입니다.
- 다음과 같은 반복해서 실행하는 Job을 운영해야 할 때 사용
- Data Backup
- Send email
- Cleaning tasks
- Cronjob Schedule: “0 3 1 * *”
- Minutes (from 0 to 59)
- Hours (from 0 to 23)
- Day of the month (from 1 to 31)
- Month (from 1 to 12) → * 기호는 전체를 의미한다.
- Day of the week (from 0 to 6) → 0이 일요일을 의미
주중 새벽 3시에 job을 실행해줘 → “0 3 * * 1-5”
주말 새벽 3시에 job을 실행해줘 → “0 3 * * 0,6”
job을 5분마다 한번씩 실행해줘 → “*/5 * * * *”
2시간마다 매시 정각에 실행해줘 → “0 */2 * * *”apiVersion: batch/v1 kind: CronJob metadata: name: cronjob-exam spec: schedule: "* * * * *" startingDeadlineSeconds: 500 concurrencyPolicy: Forbid # concurrencyPolicy: Allow 실행이 아직 끝나지 않아도 다음 작업이 시작할 수 있다. jobTemplate: spec: template: spec: containers: - name: hello image: busybox args: - /bin/sh - -c - echo Hello; sleep 10; echo Bye restartPolicy: Never- 위 yaml 파일이 실행되면 1분마다 pod가 새로 생성되면서 cronJob이 진행됩니다.

참고로 successfulJobsHistoryLimit 옵션이 있는데 성공한 job들을 최대 설정 값 까지만 pod로 남기고 나머지 pod는 자동으로 삭제해 줍니다. 기본값은 3개입니다.
지금까지 쿠버네티스 실습 환경 및 기본 개념과 Pod, Controller에 대해 알아봤습니다. 다음 글에서는 Service 와 Ingress 및 추가 기능들에 대해 알아보도록 하겠습니다.